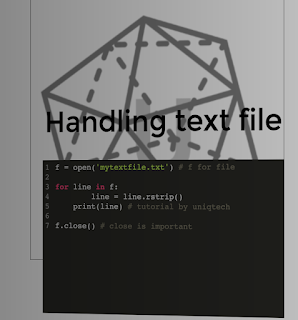
|
What does training data look like in image classification tasks?
Images are separated into train, valid folders.
Within each folder, images are organized by the numeric value corresponding to their class name e.g.0,1,2. ... usually starting from 0 to the number of classes minus 1 when it is zero-indexed. Else it starts at 1.
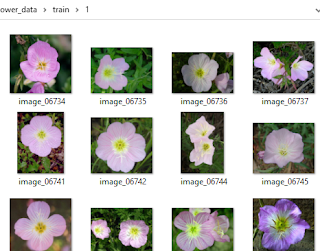
This is what the oxford flower dataset looks like
We talked extensively about having a framework for understanding machine learning - the machine learning workflow. We published a simplified (crystalized) version of the workflow. We refer to it very often, because it is such a useful framework. Check out the list. We also routinely compare this workflow with workflow illustrations from leading engineering companies to check if it is still valid and relevant. Here is Uber Engineer's machine learning workflow.
https://ml.learn-to-code.co/topic_machine_learning_workflow.html

web3 tech stack illustrated by web3 foundation
 |
| 5 layers of web3 stack, layer 0 through 5 illustrated by web3 foundation. |
NVIDIA CMP HX dedicated GPU for professional mining: Remember at the beginning of the year, NVIDIA wants crypto miners to stop snatching up GPUs from gamers and instead using this device to mine professionally.

#hardware #trend #GPU #crypto #mining


NFT
 |
Check out this video by MomentRank



https://twitter.com/kissingsky/status/1428368687644364805?s=20
"Scaling to Very Very Large Corpora forNatural Language Disambiguation", Michele Banko and Eric Brill, Microsoft Research, 2001 paper

 |
| Uniqtech virtual office tour |
 |
Pandas Profiling (not an official part of pandas, it is a pypl package) provide summary statistics, calculate important stats, beyond the basic df.describe(). It has 7000+ stars and 1000+ forks. It can calculate type inference, histogram, missing values, correlation automatically.

Need to brush up on GPT-3 knowledge? Check out our GPT-3 knowledge landing page. It's free. Log in to access for free. Uniqtech Guide to understanding GPT-3. Scroll to the bottom to read all about Codex.
Uniqtech Guide to OpenAI Codex Basics

Link to our knowledge flash cards:
 |
| OpenAI Codex insights, notes, demos summarized for pro members. A big time saver. |


01 Copy and paste first grade math question from a worksheet
02 Use the question as a prompt and get an answer from OpenAI Codex
03 Codex translates the prompt from English to Python Code
04 Codex generates a numeric answer to the math question.
You can copy and paste the code into a notepad to customize.
 |
| OpenAI Codex answers first grade math questions Uniqtech Guide to Codex |


Our data visualization for job postings of Product Manager, Program Manager and Data Engineer.
Click the image to view a larger version, styling our logo. Keep in mind, our initial analysis is limited as we are just starting to collect big tech data. As our dataset grow, these insights may evolve. The difference between product and program management is still subtle, but in reality they are very different positions. We have friends doing both. The team hopes to see the visualization to be more informative soon.






Imputation is used when handling pre-processing training data in machine learning. It is useful in handling missing data.
import numpy as np # linear algebra
import seaborn as sns # data visualization, API
from bs4 import BeautifulSoup as soup # web scraping
$sudo pip install -r requirements.txt
from sklearn.metrics import roc_auc_score
from sklearn.ensemble import RandomForestClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.neighbors import KNeighborsClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import AdaBoostClassifier
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.linear_model import LogisticRegression
Workflow : How to generate or collect, preprocess and train with data.
Sample tasks :
xkcd machine learning joke https://xkcd.com/1838/
Generative Adversarial Networks (GANs)



Headspace office has an open amphitheater for group meditation and meeting, improving happiness, wellness.

Quora is a place where people go ask questions, and get relevant answers / tips back from experts, the crowd, people with experiences... What does it take to be an engineer at Quora? This recruiting flyer tells us what it really takes to be a part of the Quora engineering team. Pro (paid) members can access this info card . Follow us for more job post analysis, career growth suggestions like this http://ml.learn-to-code.co/.

 |
This is a state-of-art collaboration among researchers and technologists at ING, Microsoft, Tu Delft ... Rembrandt Museum. This is a perfect example of AI generated fine art. Unlike hobbyist generated pictures, and unlike prototype experimental art generation, this is high fidelity, fine grained, HD generated fine art, meticulously 3D printed, which is hard to achieve. In this case, it is executed to perfection. Title: Next Rembrandt - Generated AI - Uniqtech curated coolest AI demo series. Original source citation : see URL link.

A warm welcome to our Winter 2020 Machine Learning Interns. It's a fantastic Stanford group.

In traditional programming, developers give computer explicit instructions in procedural top down scripts and or via control flow statements that can “jump around” as opposed to top-down. Machine learning and deep learning is about supplying well-known, proven algorithms with cleaned, feature selected and or feature engineered data, as well as corresponding labels for the data (in unsupervised learning, only data is supplied), the algorithm leverage loss calculation, metrics, and optimizer to update parameters such as weights and coefficients in the algorithm. Finally these learned weights and coefficients are used along with the algorithm for prediction.
The more high quality data the better.
The biggest difference is: developers give specific instructions in traditional programming, and in machine learning and deep learning algorithms learn parameters based on data and loss function rather than rules.
Not having to write all the rules has benefits especially when the rules are hard to encode or program. The final product is also more robust, less likely to fail because it is not a strict rule based program.
Deep learning uses many layers of neural networks, hence the word deep. It is usually consisted of weight-learning layers or neural networks. Neural networks stacked together, have the unique capability of being universal function approximation - representing complex functions without explicitly coding them.